本文所讨论的均为AMD公司的显卡产品
显卡:AMD Radeon RX 5500 - 8GB 显存
Linux:Linux-5.4.y (fc944ddc0b4a )
背景 现代的驱动模型中,一般有2种方式来操作硬件:
PUSH :CPU通过读写寄存器的方式来控制GPU硬件。PULL :CPU将命令写到一块buffer中,并通知硬件,由硬件来解析命令并执行。
2种模式各有优劣,使用PUSH 的方式一般都为同步操作,需要占用CPU时间,并且在GPU领域有大量的寄存器是不方便用户直接读写的,所以GPU大多数采用的是PULL 方式。因此本文主要介绍AMD KMD Ring Buffer的原理和实现。
AMD GPU Ring Buffer
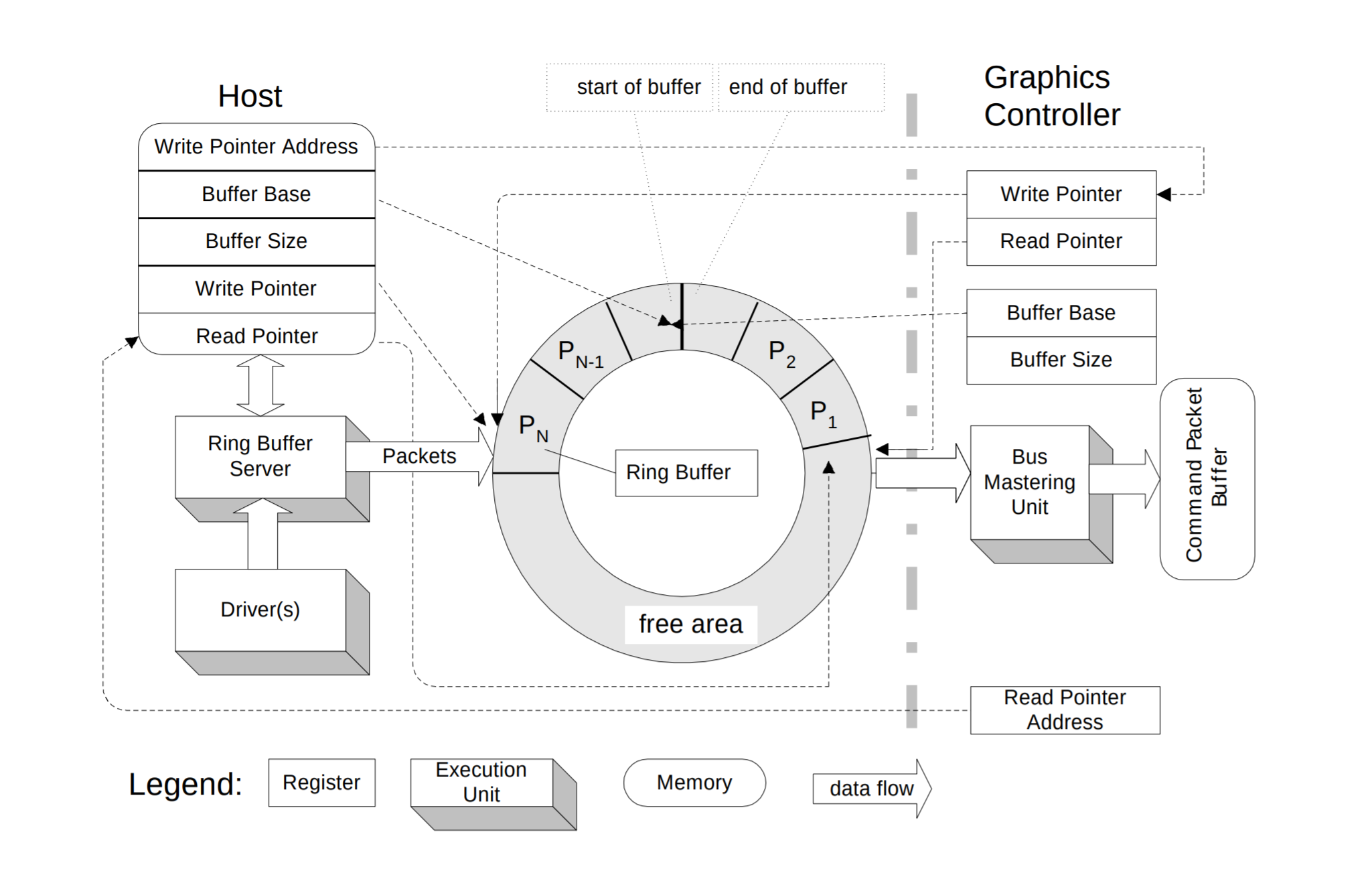
在软件领域,生产消费模型是一个典型的软件模型,一端负责生产数据,另一端负责消费数据,两端通过某种规则建立一种数据通道来达到通信的目的,同样的在GPU领域,CPU作为生产者,产生命令,GPU作为消费者,解析并执行命令,因此CPU和GPU就完成了通信。
在KMD驱动中,CPU通过一个Ring Buffer的软件模型和硬件进行通信,Ring Buffer就是一个环形缓冲区,内部有wptr和rptr来维护Ring的状态,在CPU写入数据的时候CPU会更新wptr,当GPU消费数据后会更新rptr, 因此GPU的状态可以大致分为2种:
rptr == wptr:Ring Buffer为空,GPU没有命令需要处理
rptr != wptr: Ring Buffer有数据,GPU解析并执行命令
Field
Description
Note
Buffer Base
唤醒缓冲区的地址
CPU/GPU都可以访问这个唤醒缓冲区
Buffer Size
唤醒缓冲区的大小
约定缓冲区的大小
Writer Pointer
写指针
CPU发送命令的时候更新wptr
Read Pointer
读指针
GPU处理完命令后更新rptr
在 AMD GPU内部,硬件会根据Engine的类型提供不同数量的Queue(Ring)和软件进行交互,相同Engine下的不同Queue会根据配置具有不同的硬件能力:
Engine
Ring Count
Note
GFX
1 - 2~
3D Graphcis: 3D and HP3D
Compute
32~
数学/矩阵计算
SDMA
(1 - 7) * 10~
System DMA 数据拷贝/填充/搬运…
UVD
1~
Unified Video Decode
VCE
1~
Video Encode Engine
AMD GPU Ring 命令类型 不同Engine定义了不同类型的命令,其中最主要的GFX/Compute Engined定义了2种命令类型:
PM4:AMD GPU内部主要的命令类型。 PM4
AQL (Architected Queuing Language): HSA 组织定义的命令类型 (Compute Only)。 HSA-AQL
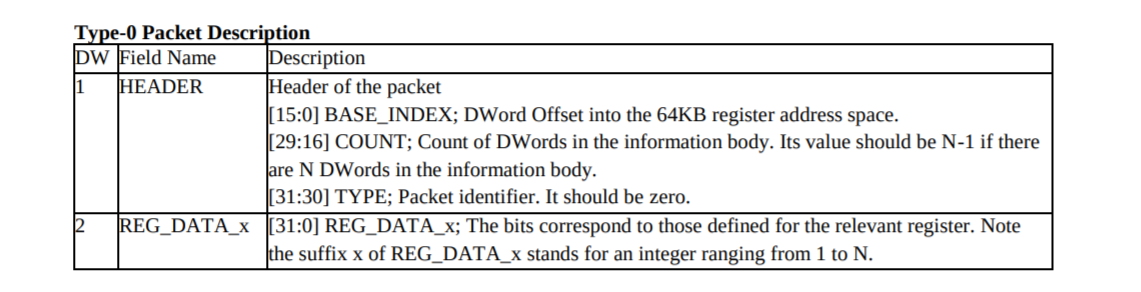
PM4: Packet 0
Type-0 Packets are discouraged, but can be used if absolutely required. Type-3 packets should be used instead. Write N DWords in the information body to the N consecutive registers, or to the register, pointed to by the BASE_INDEX field of the packet header. Does check for context roll. This packet supports a register memory map up to 64K DWords (256K Bytes).
PM4: Packet 1
Not Support.
PM4: Packet 2
This is a filler packet. It has only the header, and its content is not important except for bits 30 and 31. It is used to fill up the trailing space left when the allocated buffer for a packet, or packets, is not fully filled. This allows the CP to skip the trailing space and to fetch the next packet.
PM4: Packet 3
Type-3 packets have a common format for their headers. However, the size of their information body may vary depending on the value of field IT_OPCODE. The size of the information body is indicated by field COUNT. If the size of the information is N DWords, the value of COUNT is N-1. In the following packet definitions, we will describe the field IT_BODY for each packet with respect to a given IT_OPCODE, and omit the header. .
Packet3 是现在GPU支持最多的命令类型
HEADER:
TYPE: 3
COUNT: IT_BODY 长度 - 1
IT_OPCODE: OP 操作码,用于表示具体的命令类型
SHADER_TYPE: GFX 或者 Compute
IT_BOBDY:根据IT_OPCODE不同,填写不同的命令内容
PKT3 IT_OPCODE 列表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 drivers/gpu/drm/amd/amdgpu/soc15d.h #define PACKET3(op, n) ((PACKET_TYPE3 << 30) | \ (((op) & 0xFF ) << 8 ) | \ ((n) & 0x3FFF ) << 16 ) #define PACKET3_COMPUTE(op, n) (PACKET3(op, n) | 1 << 1) .... #define PACKET3_NOP 0x10 #define PACKET3_SET_BASE 0x11 #define PACKET3_BASE_INDEX(x) ((x) << 0) #define CE_PARTITION_BASE 3 #define PACKET3_CLEAR_STATE 0x12 #define PACKET3_INDEX_BUFFER_SIZE 0x13 #define PACKET3_DISPATCH_DIRECT 0x15 #define PACKET3_DISPATCH_INDIRECT 0x16 #define PACKET3_ATOMIC_GDS 0x1D #define PACKET3_ATOMIC_MEM 0x1E .... #define PACKET3_STRMOUT_BUFFER_UPDATE 0x34 ``` #define PACKET3(op, n) ((PACKET_TYPE3 << 30) | \ (((op) & 0xFF ) << 8 ) | \ ((n) & 0x3FFF ) << 16 ) #define PACKET3_COMPUTE(op, n) (PACKET3(op, n) | 1 << 1) .... #define PACKET3_NOP 0x10 #define PACKET3_SET_BASE 0x11 #define PACKET3_BASE_INDEX(x) ((x) << 0) #define CE_PARTITION_BASE 3 #define PACKET3_CLEAR_STATE 0x12 #define PACKET3_INDEX_BUFFER_SIZE 0x13 #define PACKET3_DISPATCH_DIRECT 0x15 #define PACKET3_DISPATCH_INDIRECT 0x16 #define PACKET3_ATOMIC_GDS 0x1D #define PACKET3_ATOMIC_MEM 0x1E .... #define PACKET3_STRMOUT_BUFFER_UPDATE 0x34
PKT3 例子 Linux AMDGPU Driver在初始化完硬件后,会进行一个简单的Ring Test:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 static int gfx_v10_0_ring_test_ring (struct amdgpu_ring *ring) struct amdgpu_device *adev = uint32_t scratch; uint32_t tmp = 0 ; unsigned i; int r; r = amdgpu_gfx_scratch_get(adev, &scratch); if (r) { DRM_ERROR("amdgpu: cp failed to get scratch reg (%d).\n" , r); return r; } WREG32(scratch, 0xCAFEDEAD ); r = amdgpu_ring_alloc(ring, 3 ); if (r) { DRM_ERROR("amdgpu: cp failed to lock ring %d (%d).\n" , ring->idx, r); amdgpu_gfx_scratch_free(adev, scratch); return r; } amdgpu_ring_write(ring, PACKET3(PACKET3_SET_UCONFIG_REG, 1 )); amdgpu_ring_write(ring, (scratch - PACKET3_SET_UCONFIG_REG_START)); amdgpu_ring_write(ring, 0xDEADBEEF ); amdgpu_ring_commit(ring); for (i = 0 ; i < adev->usec_timeout; i++) { tmp = RREG32(scratch); if (tmp == 0xDEADBEEF ) break ; if (amdgpu_emu_mode == 1 ) msleep(1 ); else udelay(1 ); } if (i < adev->usec_timeout) { if (amdgpu_emu_mode == 1 ) DRM_INFO("ring test on %d succeeded in %d msecs\n" , ring->idx, i); else DRM_INFO("ring test on %d succeeded in %d usecs\n" , ring->idx, i); } else { DRM_ERROR("amdgpu: ring %d test failed (scratch(0x%04X)=0x%08X)\n" , ring->idx, scratch, tmp); r = -EINVAL; } amdgpu_gfx_scratch_free(adev, scratch); return r; }
命令解析:
分配一个scrathch寄存器
使用CPU将其初始化为 0xCAFEDEAD
在Ring Buffer里分配一个 3 + 1 长度空间
填写命令头
PACKET3_SET_UCONFIG_REG: 命令类型,设置某一个寄存器的值
1: IT_BODY 长度为 1 + 1
scratch - PACKET3_SET_UCONFIG_REG_START: 寄存器地址
0xDEADBEEF:寄存器值
提交命令(更新wptr)到GPU
检查scratch寄存器的内容是否有变化:
如果寄存器内容从 0xCAFEDEAD变化成 0xDEADEEF则表示命令执行成功,Ring工作正常
AMD GPU Inidirect Command Buffer Indirect Command Buffer又称为IB ,是AMD GPU最常用的PKT3类型的命令包,主要功能就是间接的执行一组Command,只需要将Command所在的地址设置到命令包中即可,这种方式非常像编程里的函数调用,但是由于硬件限制,仅可以被调用一次,不可以嵌套执行。
PKT3: INDIRECT BUFFER
HEADER: 包含命令类型,长度,OP等信息
IB_BASE_LO | IB_BASE_HI: Command包在GPU视角下的地址
VMID: 因为命令包可以从不同VMID下发送下来,需要指定VMID才可以根据IB地址确定最终的物理地址
IB_SIZE: Command包的长度
PKT3: INDIRECT BUFFER 例子 AMD GPU KMD驱动在初始化结束的时候,同样会做一个简单的IB 测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 static int gfx_v10_0_ring_test_ib (struct amdgpu_ring *ring, long timeout) struct amdgpu_device *adev = struct amdgpu_ib ib ; struct dma_fence *f =NULL ; uint32_t scratch; uint32_t tmp = 0 ; long r; r = amdgpu_gfx_scratch_get(adev, &scratch); if (r) { DRM_ERROR("amdgpu: failed to get scratch reg (%ld).\n" , r); return r; } WREG32(scratch, 0xCAFEDEAD ); memset (&ib, 0 , sizeof (ib)); r = amdgpu_ib_get(adev, NULL , 256 , &ib); if (r) { DRM_ERROR("amdgpu: failed to get ib (%ld).\n" , r); goto err1; } ib.ptr[0 ] = PACKET3(PACKET3_SET_UCONFIG_REG, 1 ); ib.ptr[1 ] = ((scratch - PACKET3_SET_UCONFIG_REG_START)); ib.ptr[2 ] = 0xDEADBEEF ; ib.length_dw = 3 ; r = amdgpu_ib_schedule(ring, 1 , &ib, NULL , &f); if (r) goto err2; r = dma_fence_wait_timeout(f, false , timeout); if (r == 0 ) { DRM_ERROR("amdgpu: IB test timed out.\n" ); r = -ETIMEDOUT; goto err2; } else if (r < 0 ) { DRM_ERROR("amdgpu: fence wait failed (%ld).\n" , r); goto err2; } tmp = RREG32(scratch); if (tmp == 0xDEADBEEF ) { DRM_INFO("ib test on ring %d succeeded\n" , ring->idx); r = 0 ; } else { DRM_ERROR("amdgpu: ib test failed (scratch(0x%04X)=0x%08X)\n" , scratch, tmp); r = -EINVAL; } err2: amdgpu_ib_free(adev, &ib, NULL ); dma_fence_put(f); err1: amdgpu_gfx_scratch_free(adev, scratch); return r; }
这个IB 测试和之前的Ring Test 一样,都是改写某一个寄存器:
分配一个scratch 寄存器
CPU修改寄存器值为0xCAFEDEAD
2为IB 分配一块buffer
填充IB 内容,内容为PACKET3_SET_UCONFIG_REG去设置寄存器
提交IB 到GPU SHCEDULER,等待调度
等待IB 执行完成
CPU检查scratch 是否成功设置为0xdeadbeef
AMD GPU HW Queue Type
PQ (Primary Queue): 主要的AMD GPU Queue
IB(Indirect Buffer): Indirect Buffer Queue
IQ(Interrupt Queue): 被挂起的Queue
EOP(End of Pipe): 用于标识Command执行完毕
其中PQ 和 IB 是比较重要的2个Queue.
AMD GPU Ring Control Ring Buffer是软件和GPU硬件沟通的主要通道,其中wptr和rptr是两个非常重要的信息,那么软件和GPU是如何交互的呢?
KMD驱动会为每一个ring分配2个DWORD分别用于存取rptr和wptr:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 r = amdgpu_device_wb_get(adev, &ring->rptr_offs); if (r) { dev_err(adev->dev, "(%d) ring rptr_offs wb alloc failed\n" , r); return r; } r = amdgpu_device_wb_get(adev, &ring->wptr_offs); if (r) { dev_err(adev->dev, "(%d) ring wptr_offs wb alloc failed\n" , r); return r; } r = amdgpu_device_wb_get(adev, &ring->fence_offs); if (r) { dev_err(adev->dev, "(%d) ring fence_offs wb alloc failed\n" , r); return r; }
这2个DWORD所占用的内存 CPU 和 GPU 都可以直接访问,这样双方就可以通过共享内存的方式进行通信,但是GPU去轮寻wptr是否变化效率很低,因此GPU硬件还提供下面集中方式来更新wptr:
操作寄存器 :通过操作专用寄存器的方式来通知GPU硬件,寄存器有权限问题,不使用于User Mode Queue。
Doorbell:使用Doorbell机制来通知GPU硬件。 doorbell
共享内存(硬件轮寻): 让GPU去轮寻某一个地址上的值是否更新,效率低。
Doorbell 1 2 3 4 5 6 7 8 9 10 11 12 13 2f:00.0 VGA compatible controller [0300]: Advanced Micro Devices, Inc. [AMD/ATI] Navi 14 [Radeon RX 5500/5500M / Pro 5500M] [1002:7340] (rev c5) (prog-if 00 [VGA controller]) Subsystem: Advanced Micro Devices, Inc. [AMD/ATI] Navi 14 [Radeon RX 5500/5500M / Pro 5500M] [1002:0b0c] Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+ Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0, Cache Line Size: 64 bytes Interrupt: pin A routed to IRQ 83 Region 0: Memory at d0000000 (64-bit, prefetchable) [size=256M] Region 2: Memory at e0000000 (64-bit, prefetchable) [size=2M] Region 4: I/O ports at f000 [size=256] Region 5: Memory at fce00000 (32-bit, non-prefetchable) [size=512K] Expansion ROM at fce80000 [disabled] [size=128K] Capabilities: <access denied> Kernel driver in use: amdgpu
Region 2: GPU 硬件提供 2M 空间的Doorbell寄存器
AMD GPU KMD驱动动态来的来管理这些Doorbell寄存器,这些寄存器可以动态的和某一个Ring进行关联,只需要将DoorBell 寄存器的Index信息设置到对应的寄存器中即可,软件就可以通过操作doorbell来达到更新wptr的目的。
doorbell的分配要符合硬件限制。
Example: GFX 更新WPTR 1 2 3 4 5 6 7 8 9 10 11 12 13 static void gfx_v10_0_ring_set_wptr_gfx (struct amdgpu_ring *ring) struct amdgpu_device *adev = if (ring->use_doorbell) { atomic64_set((atomic64_t *)&adev->wb.wb[ring->wptr_offs], ring->wptr); WDOORBELL64(ring->doorbell_index, ring->wptr); } else { WREG32_SOC15(GC, 0 , mmCP_RB0_WPTR, lower_32_bits(ring->wptr)); WREG32_SOC15(GC, 0 , mmCP_RB0_WPTR_HI, upper_32_bits(ring->wptr)); } }
如果ring支持doorbell操作,就使用分配好的doorbell来更新wptr值
如果ring不支持doorbell,就使用更新寄存器的方式来更新wptr
AMD GPU Ring HW Fence AMD GPU KMD在初始化ring的时候除了分配wptr 和 rptr还会分配一个fence的DWORD,用于接受GPU传递的信息。
Fence Emit
PACKET3_RELEASE_MEM: 用于产生一个EOP事件,标识硬件已经执行完一组命令,可以释放一些硬件资源,并将一个软件标记写入到指定内存地址,并产生一个硬件中断来通知软件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 static void gfx_v10_0_ring_emit_fence (struct amdgpu_ring *ring, u64 addr, u64 seq, unsigned flags) struct amdgpu_device *adev = bool write64bit = flags & AMDGPU_FENCE_FLAG_64BIT; bool int_sel = flags & AMDGPU_FENCE_FLAG_INT; if (adev->pdev->device == 0x50 ) int_sel = false ; amdgpu_ring_write(ring, PACKET3(PACKET3_RELEASE_MEM, 6 )); amdgpu_ring_write(ring, (PACKET3_RELEASE_MEM_GCR_SEQ | PACKET3_RELEASE_MEM_GCR_GL2_WB | PACKET3_RELEASE_MEM_GCR_GLM_INV | PACKET3_RELEASE_MEM_GCR_GLM_WB | PACKET3_RELEASE_MEM_CACHE_POLICY(3 ) | PACKET3_RELEASE_MEM_EVENT_TYPE(CACHE_FLUSH_AND_INV_TS_EVENT) | PACKET3_RELEASE_MEM_EVENT_INDEX(5 ))); amdgpu_ring_write(ring, (PACKET3_RELEASE_MEM_DATA_SEL(write64bit ? 2 : 1 ) | PACKET3_RELEASE_MEM_INT_SEL(int_sel ? 2 : 0 ))); if (write64bit) BUG_ON(addr & 0x7 ); else BUG_ON(addr & 0x3 ); amdgpu_ring_write(ring, lower_32_bits(addr)); amdgpu_ring_write(ring, upper_32_bits(addr)); amdgpu_ring_write(ring, lower_32_bits(seq)); amdgpu_ring_write(ring, upper_32_bits(seq)); amdgpu_ring_write(ring, 0 ); }
初始化 PACKET3_RELEASE_MEM header
设置是否要产生硬件中断
设置标记地址
设置标记内容
因为在GPU硬件中,PKT3一般都是顺序执行的,这条PKT执行完毕后,会产生一个硬件终端,并标这条PKT之前的命令都已经执行完毕。
seq是软件维护的一个单调递增的数字标记,用于表示pkt执行的位置。(Per-Ring)
当硬件执行收到中断后,会在中断处理函数中释放fence,并按照dma-fence接口通知关心这个事件的人。
Fence Process 当GPU收到硬件的中断后,会根据中断所提供的信息,路由到具体ring中,并执行amdgpu_fence_process()函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 bool amdgpu_fence_process (struct amdgpu_ring *ring) struct amdgpu_fence_driver *drv = uint32_t seq, last_seq; int r; do { last_seq = atomic_read(&ring->fence_drv.last_seq); seq = amdgpu_fence_read(ring); } while (atomic_cmpxchg(&drv->last_seq, last_seq, seq) != last_seq); if (del_timer(&ring->fence_drv.fallback_timer) && seq != ring->fence_drv.sync_seq) amdgpu_fence_schedule_fallback(ring); if (unlikely(seq == last_seq)) return false ; last_seq &= drv->num_fences_mask; seq &= drv->num_fences_mask; do { struct dma_fence *fence , **ptr ; ++last_seq; last_seq &= drv->num_fences_mask; ptr = &drv->fences[last_seq]; fence = rcu_dereference_protected(*ptr, 1 ); RCU_INIT_POINTER(*ptr, NULL ); if (!fence) continue ; r = dma_fence_signal(fence); if (!r) DMA_FENCE_TRACE(fence, "signaled from irq context\n" ); else BUG(); dma_fence_put(fence); } while (last_seq != seq); return true ; }
因为IRQ的负载均衡的原因,中断可能被分配到不同的cpu上,这里采用类似读写锁的方式来保证各个cpu上处理的fence不会冲突
因为fence在发射的时候还会额外启动一个定时器,当定时器超时后,会强制处理fence,这里重新调整定时器延迟
使用dma_fence提供的signal接口,依次调用cb函数,来通知关心这个fence的人。
总结 本文简单的介绍了一下KMD下实现的Ring Buffer,希望能对你有所帮助。