本文所讨论的均为AMD公司的显卡产品
显卡:AMD Radeon RX 5500 - 8GB 显存
Linux:Linux-5.4.y (fc944ddc0b4a )
GPU的分类 GPU又称之为显卡,在计算机里面扮演着图形渲染和并行计算的角色,今天我们就来聊一聊GPU的物理内存。
现代的计算机显卡按照内存的类型分为2种:
UMA :U nified M emory A rchitecture, 统一内存架构,一般认为是集成显卡dGPU : D iscrete GPU 独立显卡
独立显卡一般配有高带宽(HBM )的显存,主要有2种:GDDRX 和 HBM显存, HBM主要用于高端显卡。
显存的大小
UMA类型的GPU没有独立的显存,一般都将系统的一部分内存做为显存,这部分显存的大小由System BIOS指定,出于安全考虑,被占用的这部分内存对与CPU来说一般为不可见的,换据话说BIOS会将这段内存设置为reserve状态,并通过e820等方式报告给系统,系统不能将这段内存作为它用dGPU类型的显卡都配有高带宽的显存,主流显存的大小为6G, 8G, 12G等,dGPU一般的通过PCIE的方式与系统相连,在32 bit系统上,因为整个物理地址空间只有4G,所以对于大容量的显存,并不能把全部的显存都映射到CPU的地址空间中供CPU访问,一般只有256M的大小的显存能被CPU直接访问,称这部分内存为visible显存,其余的部分为invisble
可以通过下面的命令查看显卡的硬件信息
1 2 3 4 5 6 7 8 9 10 11 12 13 $ lspci -vvvnnn -s 2f:00.0 2f:00.0 VGA compatible controller [0300]: Advanced Micro Devices, Inc. [AMD/ATI] Navi 14 [Radeon RX 5500/5500M / Pro 5500M] [1002:7340] (rev c5) (prog-if 00 [VGA controller]) Subsystem: Advanced Micro Devices, Inc. [AMD/ATI] Navi 14 [Radeon RX 5500/5500M / Pro 5500M] [1002:0b0c] Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx- Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0, Cache Line Size: 64 bytes Interrupt: pin A routed to IRQ 255 Region 0: Memory at d0000000 (64-bit, prefetchable) [size=256M] Region 2: Memory at e0000000 (64-bit, prefetchable) [size=2M] Region 4: I/O ports at f000 [disabled] [size=256] Region 5: Memory at fce00000 (32-bit, non-prefetchable) [size=512K] Expansion ROM at fce80000 [disabled] [size=128K] Capabilities: <access denied>
Region 0 是显存的MMIO空间,在没有打开Large Bar功能的时候,显存会被映射到CPU的低4G地址空间,并且最多只有256M。Region 2 是Doorbell的MMIO空间,用于实现软件通知硬件的一种方式,值得注意的是,这部分空间是prefetchable 的,并且可以映射到用户空间Region 4 是显卡的IO空间Region 5 是显卡寄存器的MMIO空间,只有512K大小,并且是non-prefetchableExpansion ROM 是显卡的BIOS在image在存储域镜像的映射,属于Option ROM是PCI-E可选的一种功能
在64 bit 系统上,由于CPU看到的地址范围很大,可以把显卡的全部显存映射到CPU存储域地址空间供CPU直接访问,默认情况下这个功能默认是关闭的,
可以在System BIOS中打开这部分功能:
1 2 3 4 5 6 7 8 9 10 11 12 $ lspci -vvvnnn -s 2f:00.0 2f:00.0 VGA compatible controller [0300]: Advanced Micro Devices, Inc. [AMD/ATI] Navi 14 [Radeon RX 5500/5500M / Pro 5500M] [1002:7340] (rev c5) (prog-if 00 [VGA controller]) Subsystem: Advanced Micro Devices, Inc. [AMD/ATI] Navi 14 [Radeon RX 5500/5500M / Pro 5500M] [1002:0b0c] Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+ Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0, Cache Line Size: 64 bytes Interrupt: pin A routed to IRQ 83 Region 0: Memory at a00000000 (64-bit, prefetchable) [size=8G] Region 2: Memory at 900000000 (64-bit, prefetchable) [size=2M] Region 4: I/O ports at f000 [size=256] Region 5: Memory at fce00000 (32-bit, non-prefetchable) [size=512K] Expansion ROM at fce80000 [disabled] [size=128K]
在打开Above 4G 功能后 Region 0:a00000000 已经被重新映射到 4G以上的地址空间上
当在系统BIOS里打开上面提到的功能,我们可以把GPU的显存完整的映射到CPU的地址空间,这样所有内存都是VISIBILE 的了,下面是AMD GPU Driver做FB Bar Resize:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 int amdgpu_device_resize_fb_bar (struct amdgpu_device *adev) u64 space_needed = roundup_pow_of_two(adev->gmc.real_vram_size); u32 rbar_size = order_base_2(((space_needed >> 20 ) | 1 )) - 1 ; struct pci_bus *root ; struct resource *res ; ... root = adev->pdev->bus; while (root->parent) root = root->parent; pci_bus_for_each_resource(root, res, i) { if (res && res->flags & (IORESOURCE_MEM | IORESOURCE_MEM_64) && res->start > 0x100000000 ull) break ; } if (!res) return 0 ; pci_read_config_word(adev->pdev, PCI_COMMAND, &cmd); pci_write_config_word(adev->pdev, PCI_COMMAND, cmd & ~PCI_COMMAND_MEMORY); amdgpu_device_doorbell_fini(adev); if (adev->asic_type >= CHIP_BONAIRE) pci_release_resource(adev->pdev, 2 ); pci_release_resource(adev->pdev, 0 ); r = pci_resize_resource(adev->pdev, 0 , rbar_size); if (r == -ENOSPC) DRM_INFO("Not enough PCI address space for a large BAR." ); else if (r && r != -ENOTSUPP) DRM_ERROR("Problem resizing BAR0 (%d)." , r); pci_assign_unassigned_bus_resources(adev->pdev->bus); r = amdgpu_device_doorbell_init(adev); if (r || (pci_resource_flags(adev->pdev, 0 ) & IORESOURCE_UNSET)) return -ENODEV; pci_write_config_word(adev->pdev, PCI_COMMAND, cmd); return 0 ; }
读到这里我想你心中会有一个疑问: 对于invisbile部分的显存CPU是如何访问呢?
答:对于invisbile的显存,CPU是没有办法直接访问的。因为现代的GPU都有DMA能力,可以访问系统层面的内存。对于GPU来说可以直接使用这部分内存,也可以将System的内存内容搬运到GPU的显存上去使用,因为系统内存带宽相对来说比较低,所以一般还是需要搬运到显存上进行计算的。
GTT 内存 GTT 是 graphics translation table 的缩写,也叫做GART(graphics aperture remapping table)允许有DMA能力的GPU硬件将系统内存作为GPU显存。
GPU除了可以使用显卡上自带的独立显存,还可以使用系统的内存做为GPU的显存,不过有别与集成显卡的那部分显存,GTT内存是可以按需分配的,并不要求在开机的过程中就reserve一段空间给GPU。
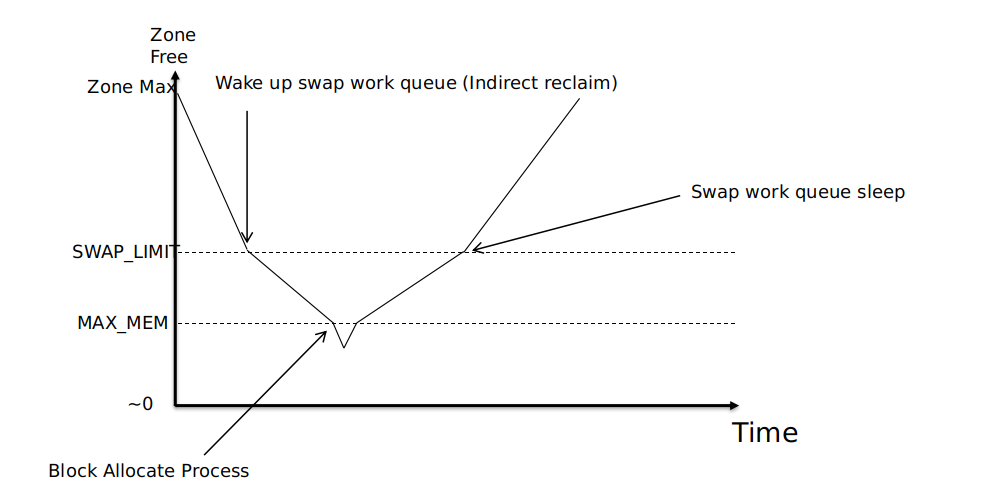
因为系统的内存也很宝贵,并不能将全部的内存都作为GTT内存,在TTM实现里一般将系统内存的 1/2 可以供给外设使用,超过这部分内存TTMdriver会进行 swap操作来回收内存,避免系统发生OOM。值得注意的是: 整个计算机硬件里可以有多张显卡,且各个显卡的厂商也可能不一样,这1/2的内存将share给所有外设使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static int ttm_mem_init_kernel_zone (struct ttm_mem_global *glob, const struct sysinfo *si) struct ttm_mem_zone *zone =sizeof (*zone), GFP_KERNEL); uint64_t mem; int ret; if (unlikely(!zone)) return -ENOMEM; mem = si->totalram - si->totalhigh; mem *= si->mem_unit; zone->name = "kernel" ; zone->zone_mem = mem; zone->max_mem = mem >> 1 ; zone->emer_mem = (mem >> 1 ) + (mem >> 2 ); zone->swap_limit = zone->max_mem - (mem >> 3 ); zone->used_mem = 0 ; zone->glob = glob; glob->zone_kernel = zone; ret = kobject_init_and_add( &zone->kobj, &ttm_mem_zone_kobj_type, &glob->kobj, zone->name); if (unlikely(ret != 0 )) { kobject_put(&zone->kobj); return ret; } glob->zones[glob->num_zones++] = zone; return 0 ; }
zone->max_mem 就是系统最多可以分给硬件内存的大小,这个大小并不是严格的系统内存1/2zone->emer_mem 具有高级权限的进程可以额外的使用一部分内存zone->swap_limit 当TTM回收内存到这个位置的时候,就停止了回收线程
这些参数主要作为TTM driver Water Mark,用来控制内存的回收时机,下面这个图可以帮你理解这些参数的作用: