AMD IOMMU 介绍
主要功能
- I/O DMA 访问权限检查和地址翻译
- 可选:支持用户VM的地址翻译
- 一个Device Table可以允许 I/O设备被分配给以个指定的domain并且包含一个指针指向Device Page Table
- 中断重映射并提供权限检查
- 可选:支持AMD64 vAPIC
- 基于内存的命令和状态交互在处理器和iommu设备之间
- 可选:支持 Peripheral Page request (PPR) Log
- 可以减轻PPR 和 Event Log Overflow
- 可选:基于硬件的允许特权I/O设备访问预定义的系统内存
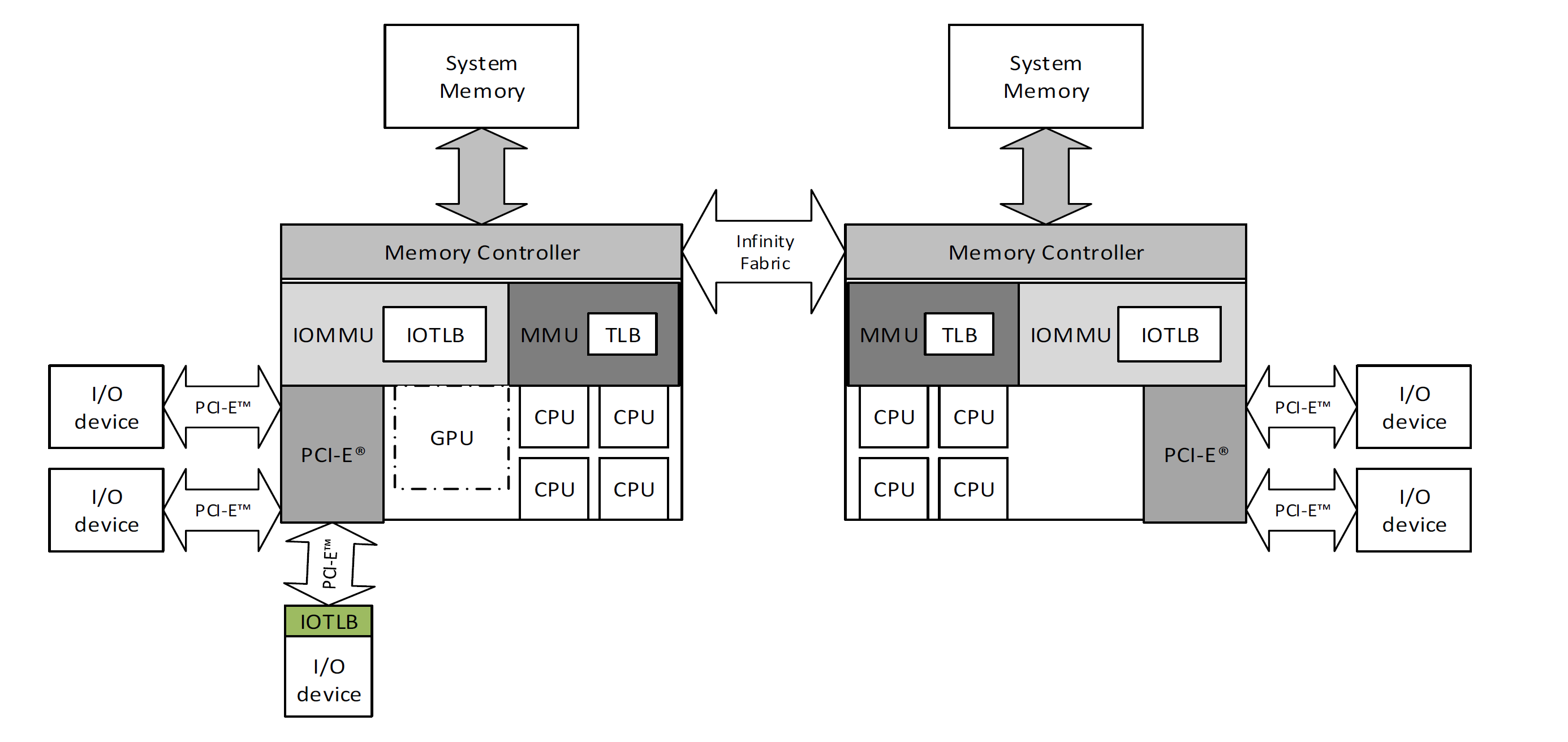
系统拓扑图
使用模型
- 替换GART(Graphic Access Remote Table)
- 替换DEV (Device Exclusion Vector)
- 对32bit设备访问64bit控制提供支持
- 用户态设备的直接访问
- 虚拟机访问设备支持
- 虚拟的IOMMU (vIOMMU)
- 虚拟化的用户态设备访问支持
IOMMU可选功能支持
- Guest virtual to guest physical address translation capability
- AMD64 long mode page table compatibility
- Support for PCI ATS
- Support for PCI-SIG PRI and PASID TLP prefix ECN
- Support for a guest virtual APIC (e.g., AVIC)
- Enhanced performance and error logging features
- Guest page table User/Supervisor access privilege checking
- Guest page table Global Supervisor-level access protection
- Guest page table non-executable page protection
- Segmentation of the Device Table
- PPR and Event Log dual buffers with optional autoswap
- PPR Auto Response with Always-on feature
- PPR Log early overflow warning
- Device-specific feature reporting registers
- MMIO access to MSI setup and mapping configuration space fields
- Memory Access Routing and Control (MARC)
- Automatic Block StopMark Message Handling
- Guest I/O Protection
- x2APIC
- Hardware Accelerated Virtualized IOMMU (vIOMMU)
- Secure ATS
- Secure Nested Paging